CVF OpenAccess arXiv pre-print View it on Github Poster
FaVoR: Features via Voxel Rendering for Camera Relocalization
(Oral presentation at WACV25)
(Nectar Track at 3DV 2026)
Vincenzo Polizzi1, Marco Cannici2, Davide Scaramuzza2, Jonathan Kelly1
1University of Toronto, 2University of Zurich
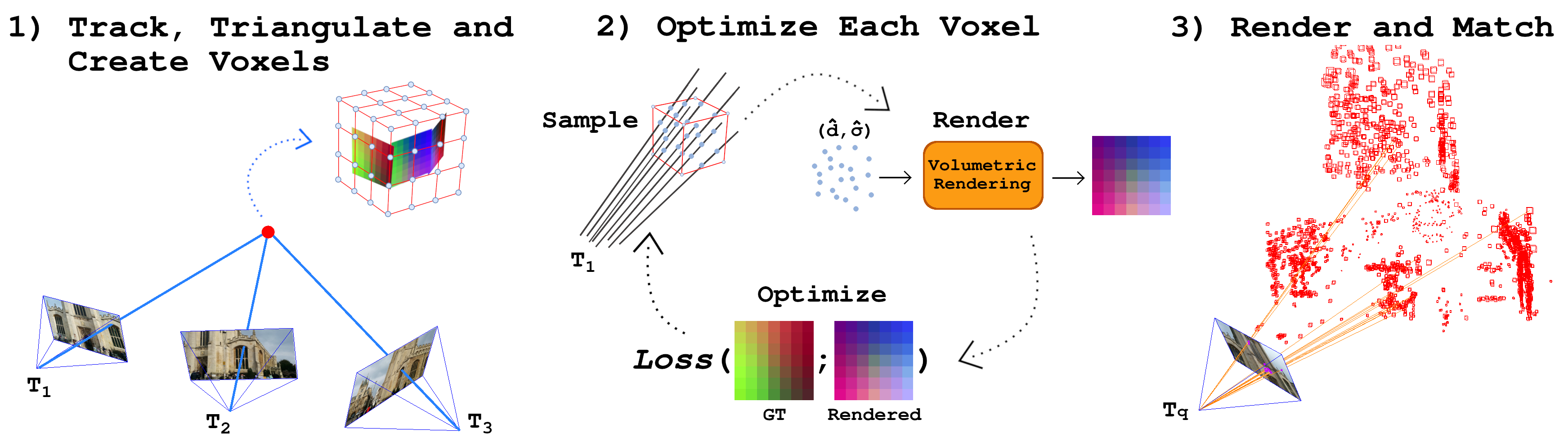
Abstract
Cambridge Landmarks Visualization





Great Court
The video below shows the camera pose relocalization computed using FaVoR. The purple frame indicates the starting camera position provided by the first DenseVLAD result, while the blue frame represents the ground truth camera pose of the query image. The estimated camera pose is shown in black, connected to the initial pose by a green line.

Move the slidebar to change camera pose.
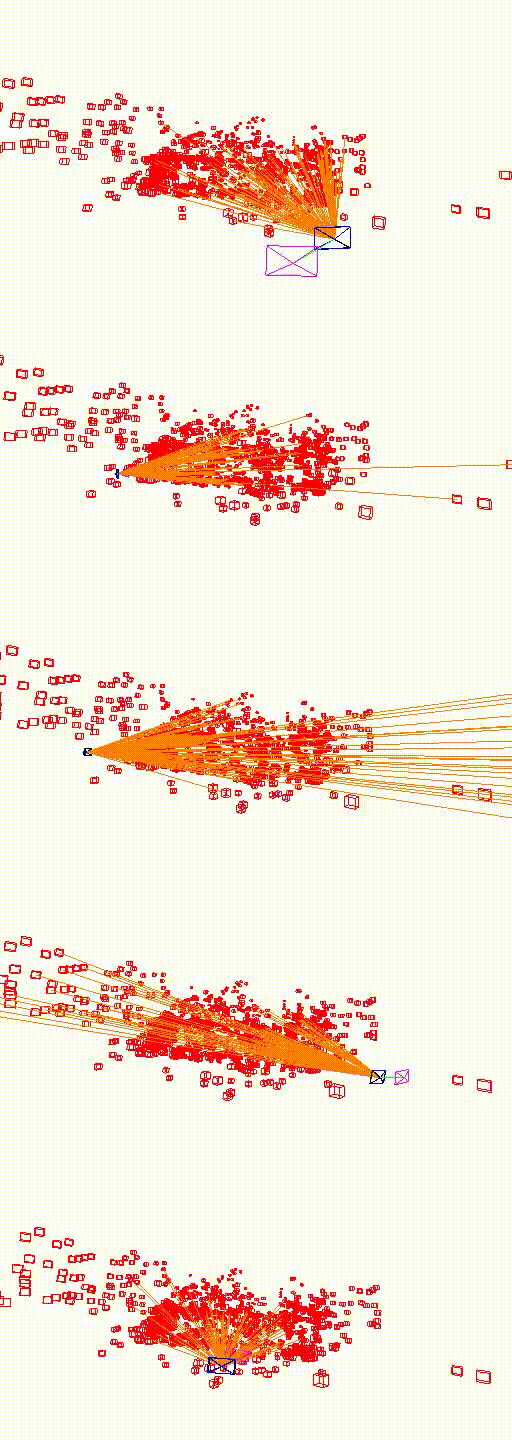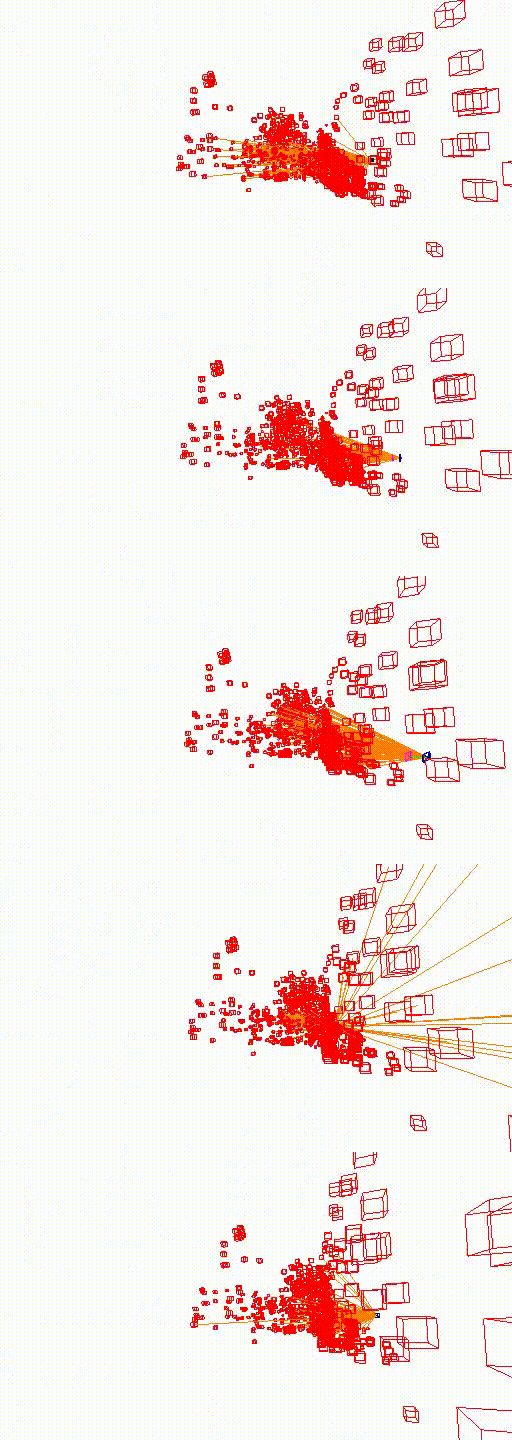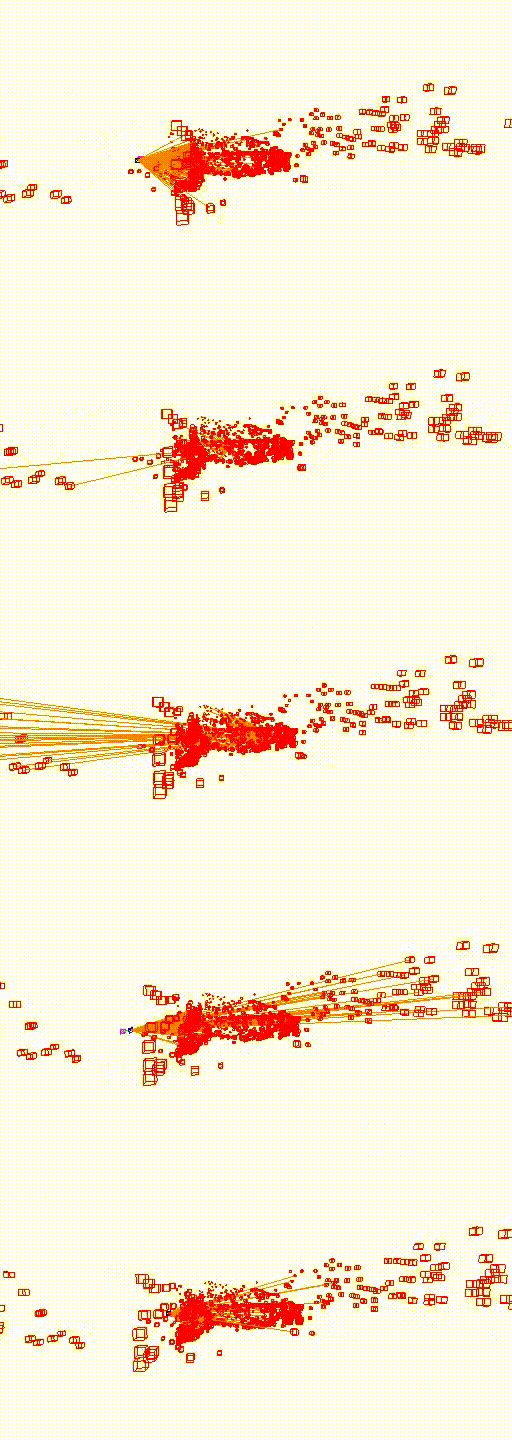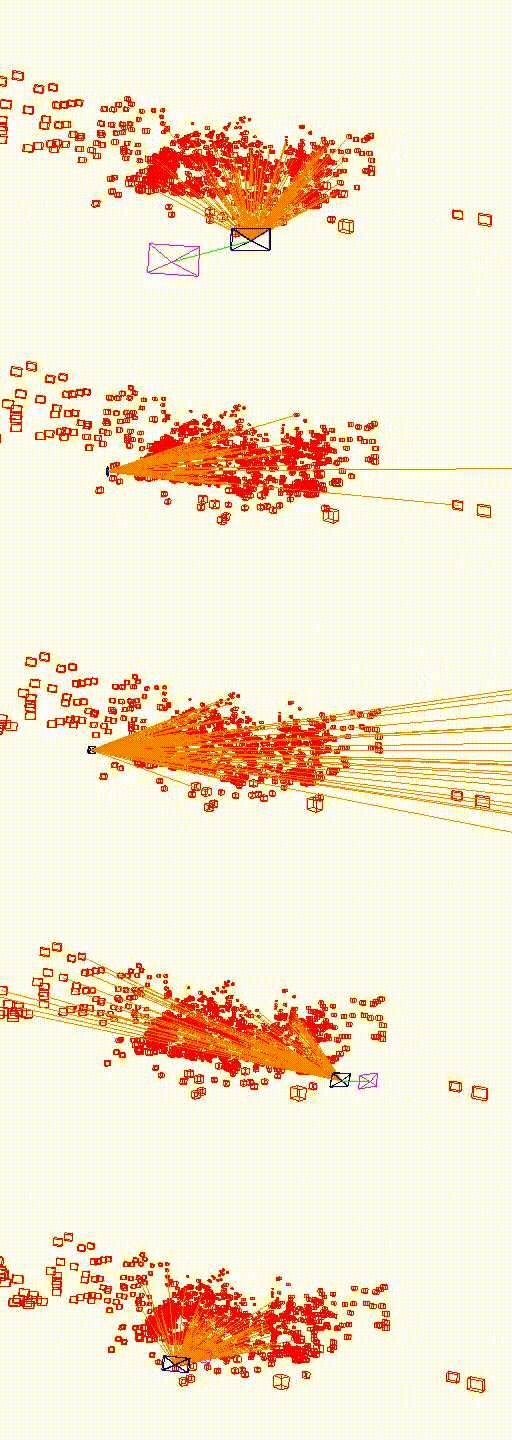
King's College
The video below shows the camera pose relocalization computed using FaVoR. The purple frame indicates the starting camera position provided by the first DenseVLAD result, while the blue frame represents the ground truth camera pose of the query image. The estimated camera pose is shown in black, connected to the initial pose by a green line.
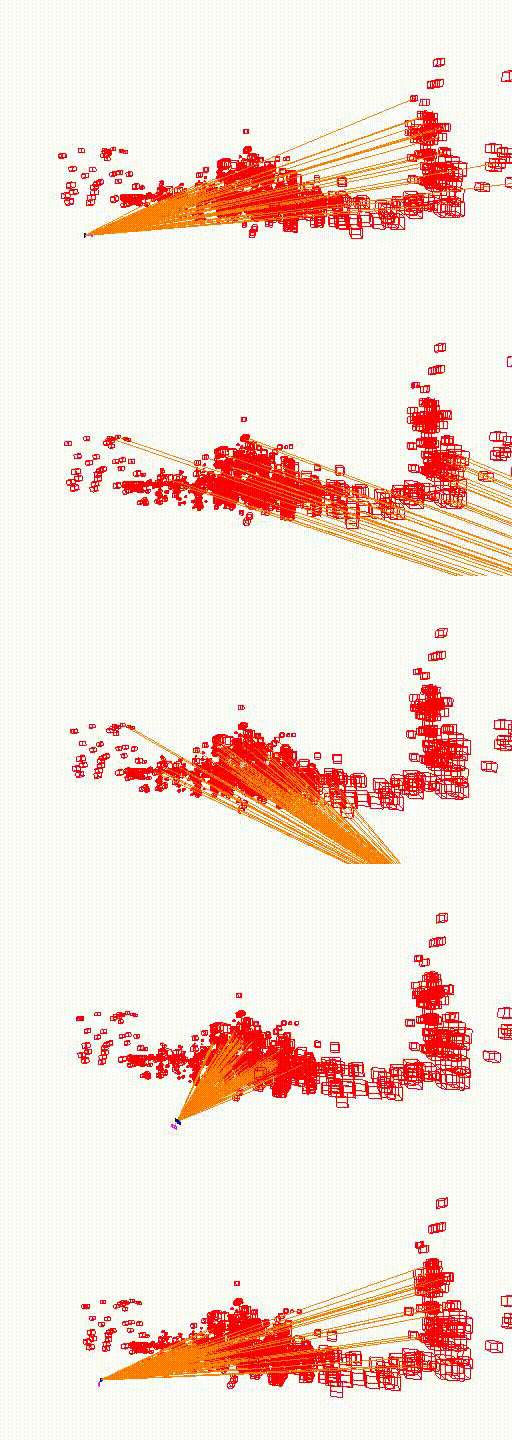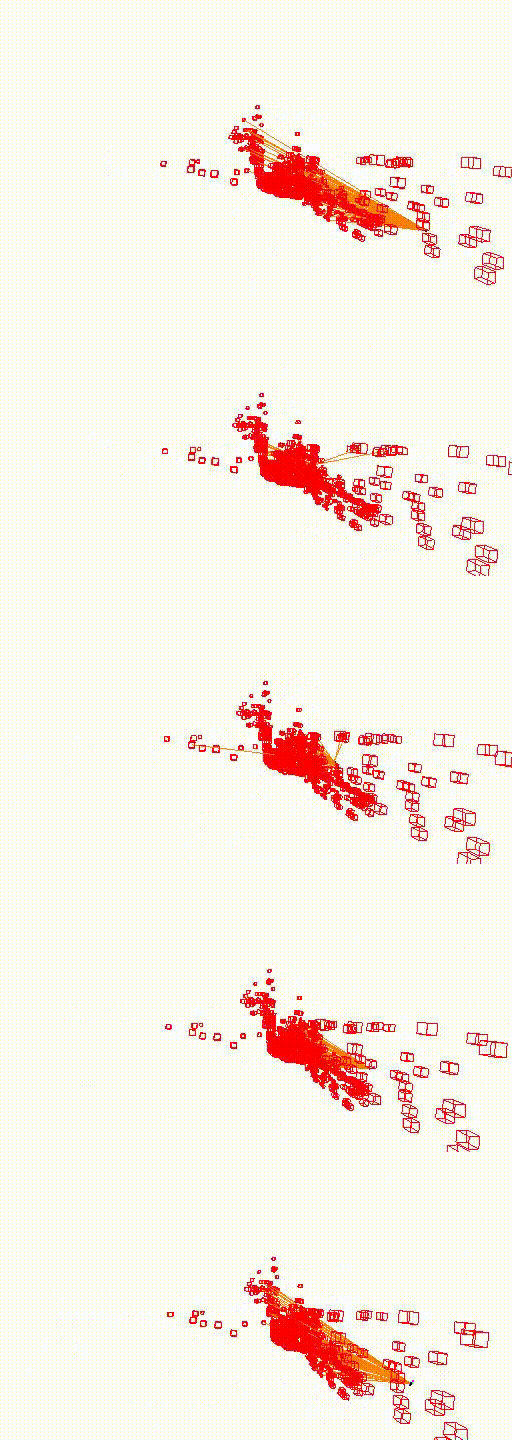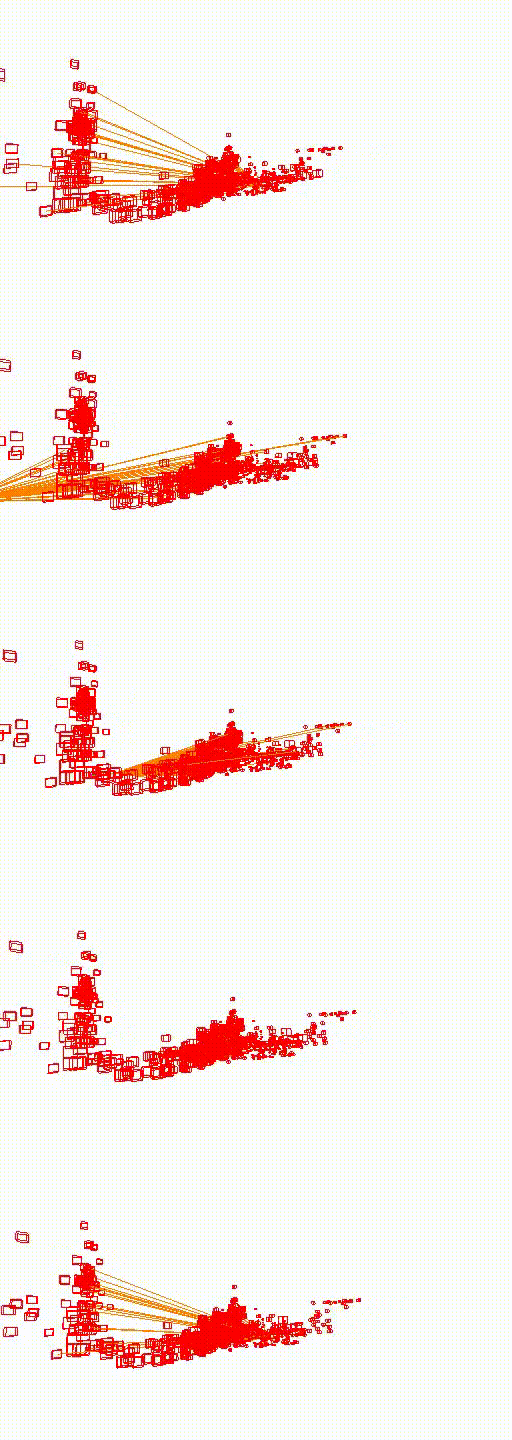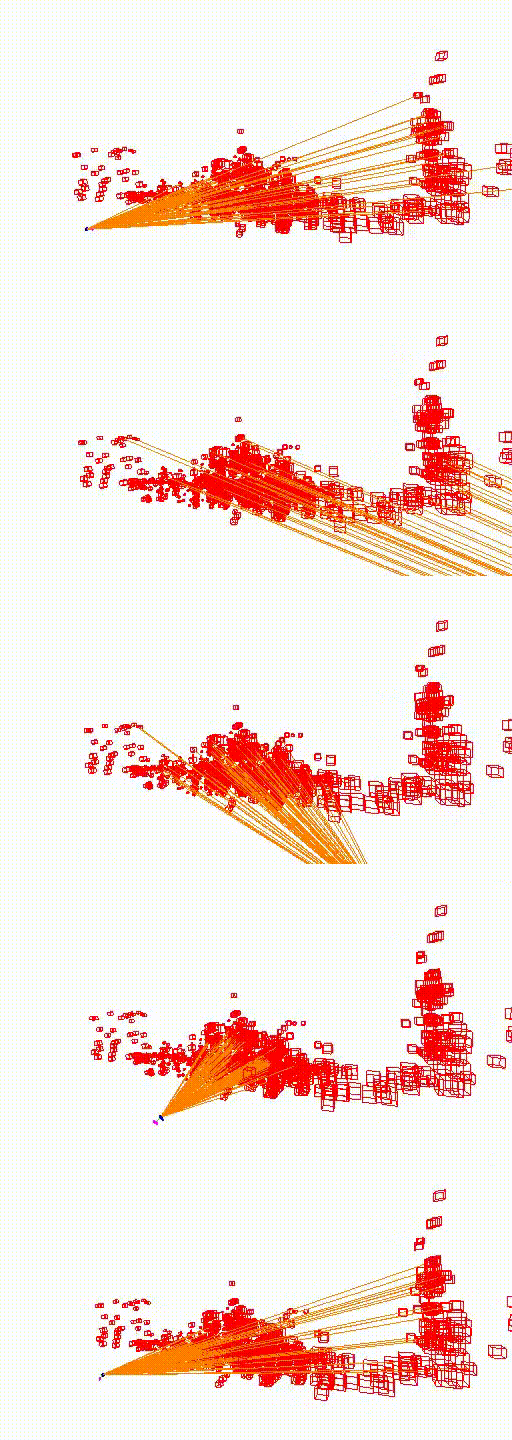
Move the slidebar to change camera pose.
Old Hospital
The video below shows the camera pose relocalization computed using FaVoR. The purple frame indicates the starting camera position provided by the first DenseVLAD result, while the blue frame represents the ground truth camera pose of the query image. The estimated camera pose is shown in black, connected to the initial pose by a green line.

Move the slidebar to change camera pose.
Shop Facade
The video below shows the camera pose relocalization computed using FaVoR. The purple frame indicates the starting camera position provided by the first DenseVLAD result, while the blue frame represents the ground truth camera pose of the query image. The estimated camera pose is shown in black, connected to the initial pose by a green line.
Move the slidebar to change camera pose.
St. Mary's Church
The video below shows the camera pose relocalization computed using FaVoR. The purple frame indicates the starting camera position provided by the first DenseVLAD result, while the blue frame represents the ground truth camera pose of the query image. The estimated camera pose is shown in black, connected to the initial pose by a green line.
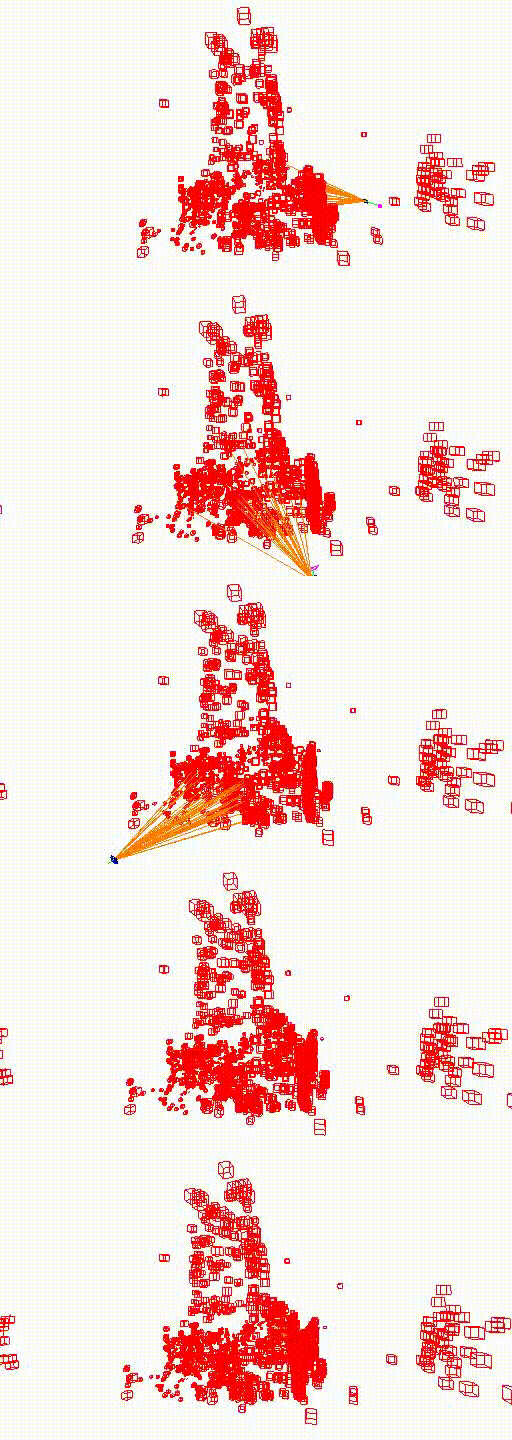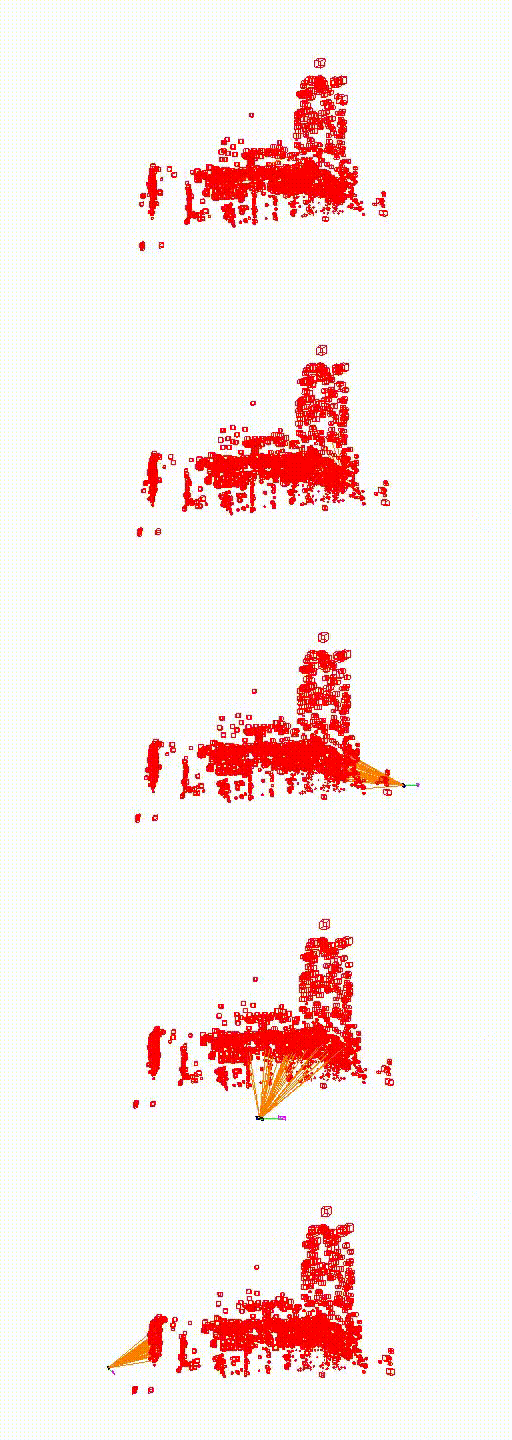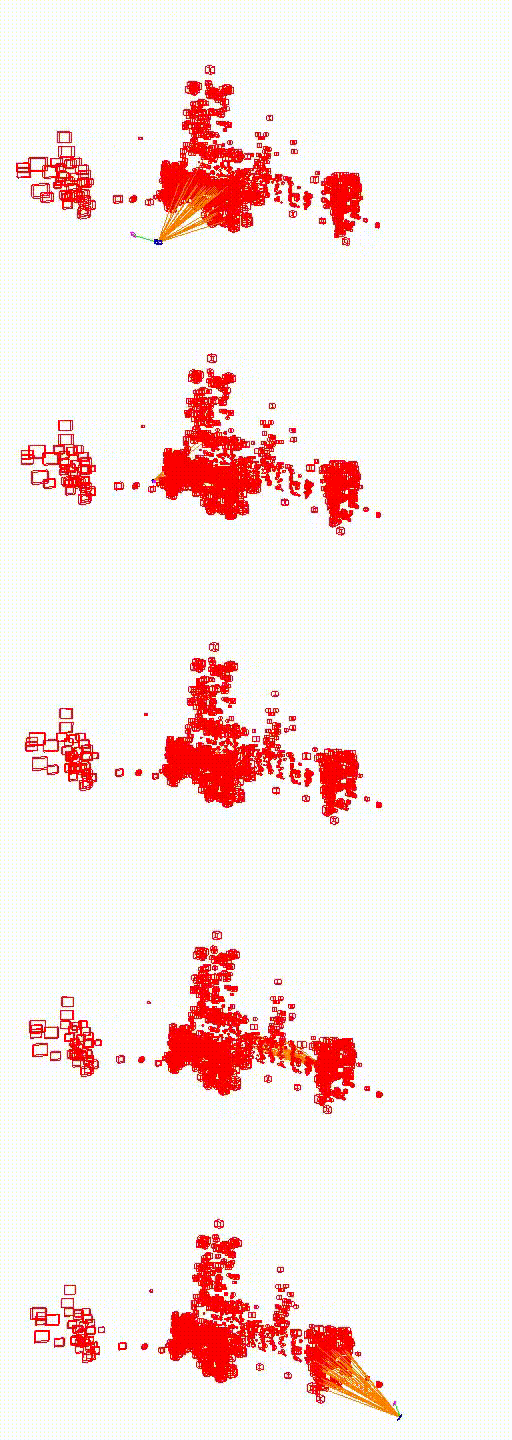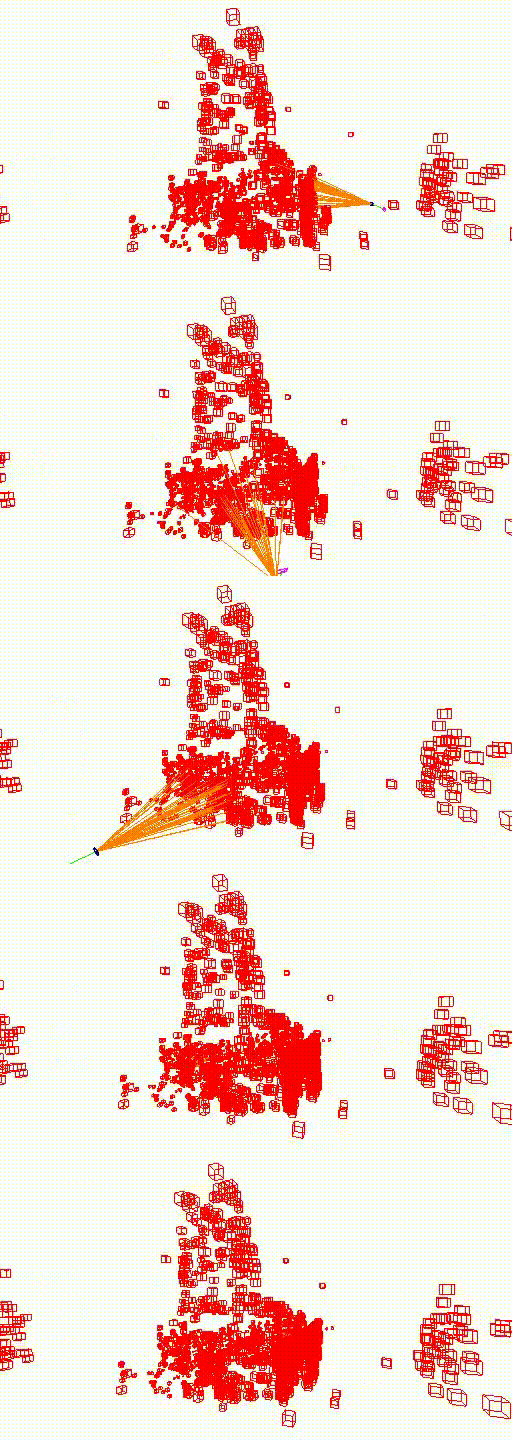
Move the slidebar to change camera pose.
FaVoR vs. Standard Features Matcher
7-Scenes Chess, features invariance
In the video below, we extract Alike-l features from a fixed target image and match these features with those extracted from a query image using standard feature matching. On the right side, we display the matches from three iterations of the FaVoR method, where FaVoR is queried using the fixed target's pose. It is noticeable that the number of matches significantly increases in the third iteration of FaVoR compared to the standard matching approach. The text at the bottom left of the image shows the distance (in meters and degrees) between the target and query images, as well as the number of matches for both methods. The text turns red when the number of standard feature matches are more than the FaVoR matches.
Rendering Capabilities
To evaluate the view invariance of feature descriptors, we extract dense descriptor maps from images taken at different angles. Using Alike-l, we compute similarity scores between features from a target image and the dense maps. The same process is applied to FaVoR, using the ground truth pose for rendering. The figure below shows the median similarity scores of the top thirty matches for both Alike-l and FaVoR across different query angles. FaVoR maintains nearly constant scores, indicating good descriptor fidelity from unseen views. In contrast, Alike-l shows a noticeable drop in similarity beyond ±30 degrees, highlighting the advantage of FaVoR in maintaining descriptor consistency across viewpoints.
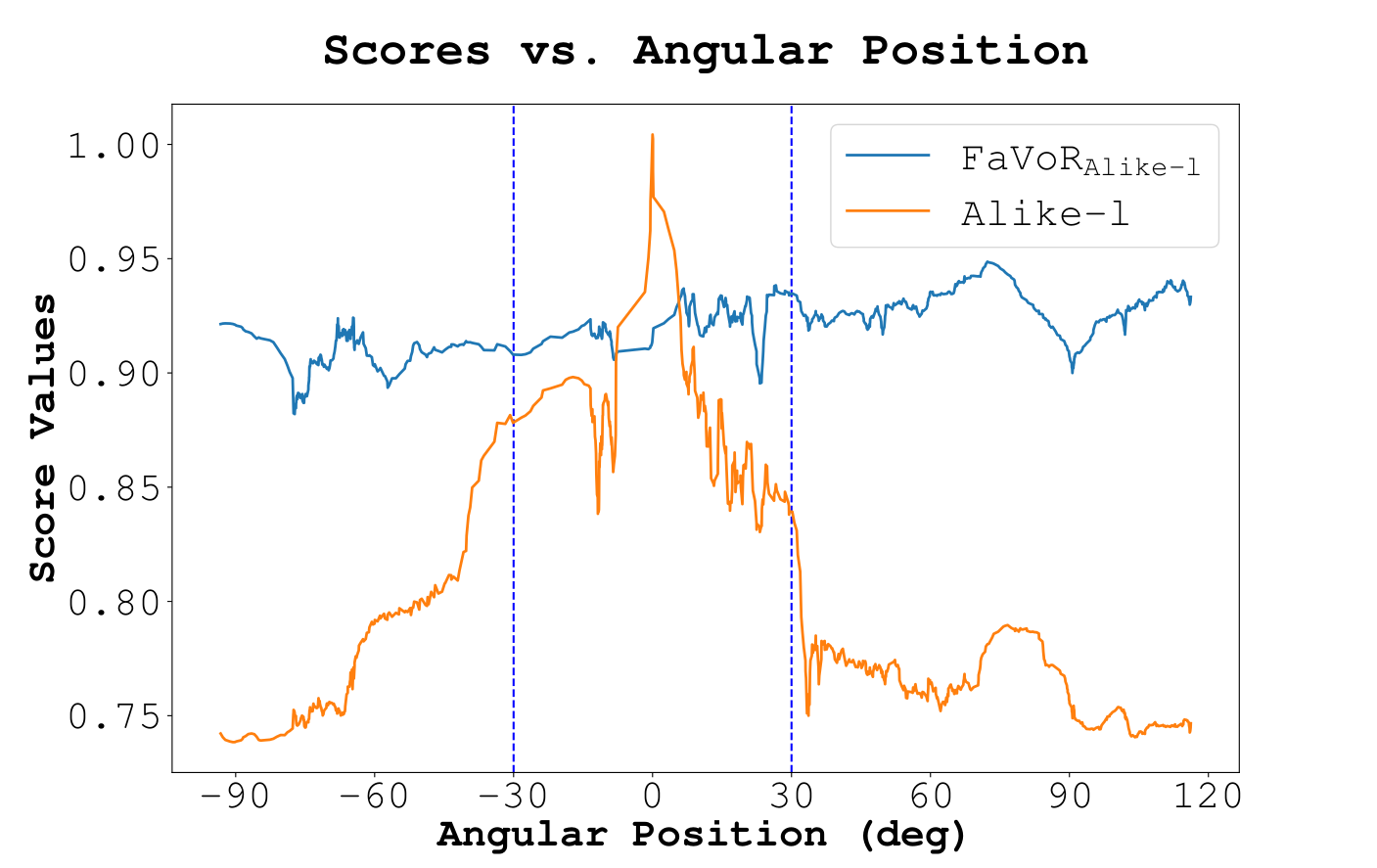
In blue is the smoothed median score for FaVoRAlike-l obtained by convolving the descriptors rendered at different view angles with the corresponding dense descriptors map of each query image. In orange is the smoothed median score of Alike-l features extracted from the starting image (at angle 0 deg) convolved with the subsequent images in the test sequence.
Results
7-Scenes Dataset
6-DoF median localization errors on the 7-Scenes dataset. Comparison of visual localization methods. The overall top three results are shown in bold, underline, and double-underline.
| Category | Method | Chess | Fire | Heads | Office | Pumpkin | Kitchen | Stairs | Average |
|---|---|---|---|---|---|---|---|---|---|
| IBMs | PoseNet17 | 13, 4.5 | 27, 11.3 | 17, 13.0 | 19, 5.6 | 26, 4.8 | 23, 5.4 | 35, 12.4 | 22.9, 8.1 |
| MapNet | 8, 3.3 | 27, 11.7 | 18, 13.3 | 17, 5.2 | 22, 4.0 | 23, 4.9 | 30, 12.1 | 20.7, 7.8 | |
| PAEs | 12, 5.0 | 24, 9.3 | 14, 12.5 | 19, 5.8 | 18, 4.9 | 18, 6.2 | 25, 8.7 | 18.6, 7.5 | |
| LENS | 3, 1.3 | 10, 3.7 | 7, 5.8 | 7, 1.9 | 8, 2.2 | 9, 2.2 | 14, 3.6 | 8.3, 3.0 | |
| HM | HLoc (RGB-D SP+SG) | 2, 0.8 | 2, 0.8 | 1, 0.8 | 3, 0.8 | 4, 1.1 | 3, 1.1 | 4, 1.2 | 2.7, 0.9 |
| SBMs | SC-WLS | 3, 0.8 | 5, 1.1 | 3, 1.9 | 6, 0.9 | 8, 1.3 | 9, 1.4 | 12, 2.8 | 6.6, 1.5 |
| DSAC* (RGB) | 2, 1.1 | 2, 1.2 | 1, 1.8 | 3, 1.2 | 4, 1.3 | 4, 1.7 | 3, 1.2 | 2.7, 1.4 | |
| ACE | 2, 1.1 | 2, 1.8 | 2, 1.1 | 3, 1.4 | 3, 1.3 | 3, 1.3 | 3, 1.2 | 2.6, 1.3 | |
| SFRMs | FQN | 4, 1.3 | 5, 1.8 | 4, 2.4 | 10, 3.0 | 9, 2.5 | 16, 4.4 | 140, 34.7 | 27.4, 7.4 |
| CROSSFIRE | 1, 0.4 | 5, 1.9 | 3, 2.3 | 5, 1.6 | 3, 0.8 | 2, 0.8 | 12, 1.9 | 4.4, 1.4 | |
| NeRF-loc | 2, 1.1 | 2, 1.1 | 1, 1.9 | 2, 1.1 | 3, 1.3 | 3, 1.5 | 3, 1.3 | 2.3, 1.3 | |
| (Ours) Alike-t | 1, 0.3 | 1, 0.5 | 1, 0.4 | 2, 0.6 | 2, 0.4 | 1, 0.3 | 4, 1.1 | 1.7, 0.5 | |
| (Ours) Alike-s | 1, 0.2 | 2, 0.6 | 1, 0.4 | 2, 0.4 | 1, 0.3 | 4, 0.9 | 5, 1.5 | 2.3, 0.6 | |
| (Ours) Alike-n | 1, 0.2 | 1, 0.4 | 1, 0.6 | 2, 0.4 | 1, 0.3 | 1, 0.3 | 6, 1.6 | 1.9, 0.5 | |
| (Ours) Alike-l | 1, 0.2 | 1, 0.3 | 1, 0.4 | 2, 0.4 | 1, 0.3 | 1, 0.2 | 3, 0.8 | 1.4, 0.4 | |
| (Ours) SP | 1, 0.2 | 1, 0.4 | 1, 0.3 | 2, 0.4 | 1, 0.3 | 1, 0.2 | 4, 1.0 | 1.6, 0.4 |
Cambridge Landmarks Dataset
6-DoF median localization errors on the Cambridge Landmarks dataset. Comparison of visual localization methods. The overall top three results are shown in bold, underline, and double-underline.
| Category | Method | College | Court | Hospital | Shop | Church | Average | Average w/o Court |
|---|---|---|---|---|---|---|---|---|
| IBMs | PoseNet | 88, 1.0 | 683, 3.5 | 88, 3.8 | 157, 3.3 | 320, 3.3 | 267, 3.0 | 163, 2.9 |
| MapNet | 107, 1.9 | 785, 3.8 | 149, 4.2 | 200, 4.5 | 194, 3.9 | 287, 3.7 | 163, 3.6 | |
| PAEs | 90, 1.5 | - | 207, 2.6 | 99, 3.9 | 164, 4.2 | - | 140, 3.1 | |
| LENS | 33, 0.5 | - | 44, 0.9 | 27, 1.6 | 53, 1.6 | - | 39, 1.2 | |
| HM | HLocSP+SG | 6, 0.1 | 10, 0.1 | 13, 0.2 | 3, 0.1 | 4, 0.1 | 7, 0.1 | 7, 0.1 |
| SceneSqueezer | 27, 0.4 | - | 37, 0.5 | 11, 0.4 | 15, 0.4 | - | 23, 0.4 | |
| SBMs | SC-WLS | 14, 0.6 | 164, 0.9 | 42, 1.7 | 11, 0.7 | 39, 1.3 | 54, 0.7 | 27, 1.1 |
| DSAC* (RGB) | 18, 0.3 | 34, 0.2 | 21, 0.4 | 5, 0.3 | 15, 0.6 | 19, 0.3 | 15, 0.4 | |
| ACE | 28, 0.4 | 42, 0.2 | 31, 0.6 | 5, 0.3 | 19, 0.6 | 25, 0.4 | 21, 0.5 | |
| SFRMs | FQN-MN | 28, 0.4 | 4253, 39.2 | 54, 0.8 | 13, 0.6 | 58, 2.0 | 881, 8.6 | 38, 1.0 |
| CROSSFIRE | 47, 0.7 | - | 43, 0.7 | 20, 1.2 | 39, 1.4 | - | 37, 1.0 | |
| NeRF-loc | 11, 0.2 | 25, 0.1 | 18, 0.4 | 4, 0.2 | 7, 0.2 | 13, 0.2 | 10, 0.3 | |
| (Ours) Alike-t | 17, 0.3 | 29, 0.1 | 20, 0.4 | 5, 0.3 | 11, 0.4 | 16, 0.3 | 13, 0.4 | |
| (Ours) Alike-s | 16, 0.2 | 32, 0.2 | 21, 0.4 | 6, 0.3 | 11, 0.4 | 17, 0.3 | 14, 0.4 | |
| (Ours) Alike-n | 18, 0.3 | 32, 0.2 | 21, 0.4 | 5, 0.2 | 11, 0.3 | 17, 0.3 | 14, 0.3 | |
| (Ours) Alike-l | 15, 0.2 | 27, 0.1 | 19, 0.4 | 5, 0.3 | 10, 0.3 | 15, 0.3 | 12, 0.3 | |
| (Ours) SP | 18, 0.3 | 29, 0.2 | 27, 0.5 | 5, 0.3 | 11, 0.4 | 18, 0.3 | 15, 0.4 |
Models Download
The models used to generate the results in the paper can be downloaded from the Hugging Face model hub. To download the models, you can use the following command, make sure the
DATASET=7Scenes # or Cambridge
SCENE=chess # or ShopFacade etc.
NETWORK=alike-l # or alike-s, alike-n, alike-t, superpoint
huggingface-cli download viciopoli/FaVoR $DATASET/$SCENE/$NETWORK/model_ckpts/model_last.tar --local-dir-use-symlinks False --local-dir /path/to/your/directory
Cite this work
@InProceedings{Polizzi_2025_WACV,
author = {Polizzi, Vincenzo and Cannici, Marco and Scaramuzza, Davide and Kelly, Jonathan},
title = {FaVoR: Features via Voxel Rendering for Camera Relocalization},
booktitle = {2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {February},
year = {2025},
pages = {44-53},
doi = {10.1109/WACV61041.2025.00015}
}