Learning from Guided Play: Improving Exploration for Adversarial Imitation Learning with Simple Auxiliary Tasks
arXiv (with Appendix) Github DOI Youtube
Trevor Ablett, Bryan Chan, Jonathan Kelly
Robotics and Automation Letters (RA-L) with IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’23) Option
Preliminary version presented as Learning from Guided Play: A Scheduled Hierarchical Approach for Improving Exploration in Adversarial Imitation Learning
Poster at Neurips 2021 Deep Reinforcement Learning Workshop
In this work, we were interested in investigating the efficacy of Adversarial Imitation Learning (AIL) on manipulation tasks. AIL is a popular form of Inverse Reinforcement Learning (IRL) in which a Discriminator, acting as a reward, and a policy are simultaneously learned using expert data. Empirically, we found that a state-of-the-art off-policy method for AIL1 is unable to effectively solve a variety of manipulation tasks. We demonstrated that this is because AIL is susceptible to deceptive rewards2, where a locally optimal policy sufficiently matches the expert distribution without necessarily solving the task. A simplified example where this occurs is shown below:
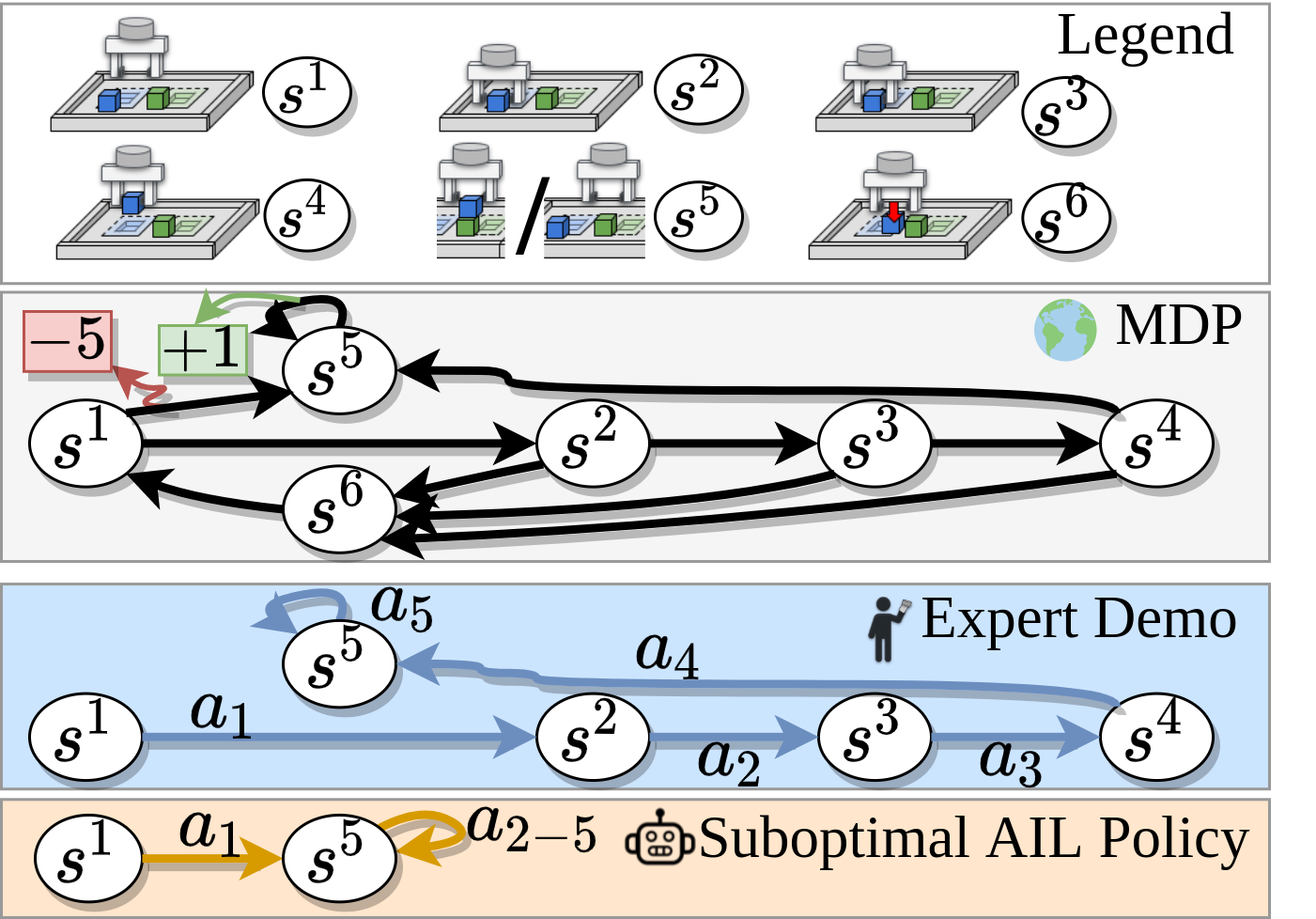
The example above can be thought of as analogous to a stacking task: \(s^2\) through \(s^6\) represent the first block being reached, grasped, lifted, moved to the second block, and dropped, respectively, while \(s^1\) is the reset state, and \(a^{15}\) represents the second block being reached without grasping the first block (action \(a^{nm}\) refers to moving from \(s^n\) to \(s^m\)). Taking action \(a^{55}\) in \(s^5\) represents opening the gripper, which results in a return of -1 after taking \(a^{15}\) (because \(R(s^1, a^{15} ) = −5\)), since the first block has not actually been grasped in this case.
AIL learns to exploit the \(a^5\) action without actually completing the full trajectory.
To mitigate this problem, we introduced a scheduled hierarchical modification3 to off-policy AIL in which multiple discriminators, policies, and critics are all learned simultaneously, solving a variety of auxiliary tasks in addition to a main task, while still ultimately attempting to maximize main task performance. We called this method Learning from Guided Play (LfGP), inspired by the play-based learning found in children, as opposed to goal-directed learning. Using expert data, the agent is guided to playfully explore parts of the state and action space that would have been avoided otherwise. The title also refers to the actual collection of this expert data, since the expert is guided by a uniform sampler, in our case, to fully explore an environment through play. This hierarchical framework not only resolved the “local maximum” policy problem exhibited by AIL, but also allowed for the reuse of expert data between tasks, increasing their expert data sample efficienty. The separation between tasks could also be easily applied to transfer learning, but we left investigating that possibility to future work.
An example of DAC’s poor performance is shown on the left side of the video at the top of the page, and the improved exploration exhibited by LfGP is shown on the right. The diagram below is a simplified description of our multitask environment and the different types of play used in our method.
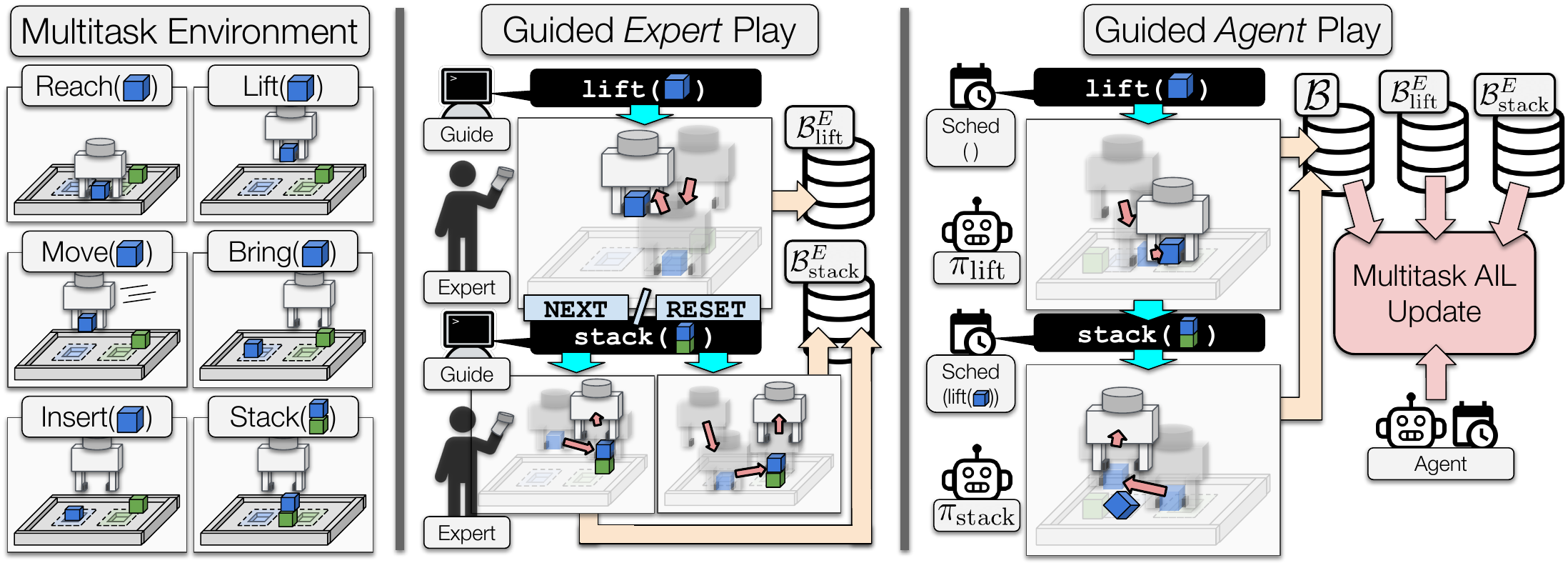
Multitask Environment
We created a simulated multitask environment which is available for use here, and is automatically installed and used when training using the open-source repository for LfGP.
Here are examples of each of the four main tasks studied in this work:
As stated, we also used simple-to-define auxiliary tasks to assist in learning and allow for the reuse of expert data and learned models:
Results
In our main performance results, we compared against the following baselines:
- Off-policy AIL (DAC1) (single-task)
- Behavioural cloning (BC) (single-task)
- BC (multitask)
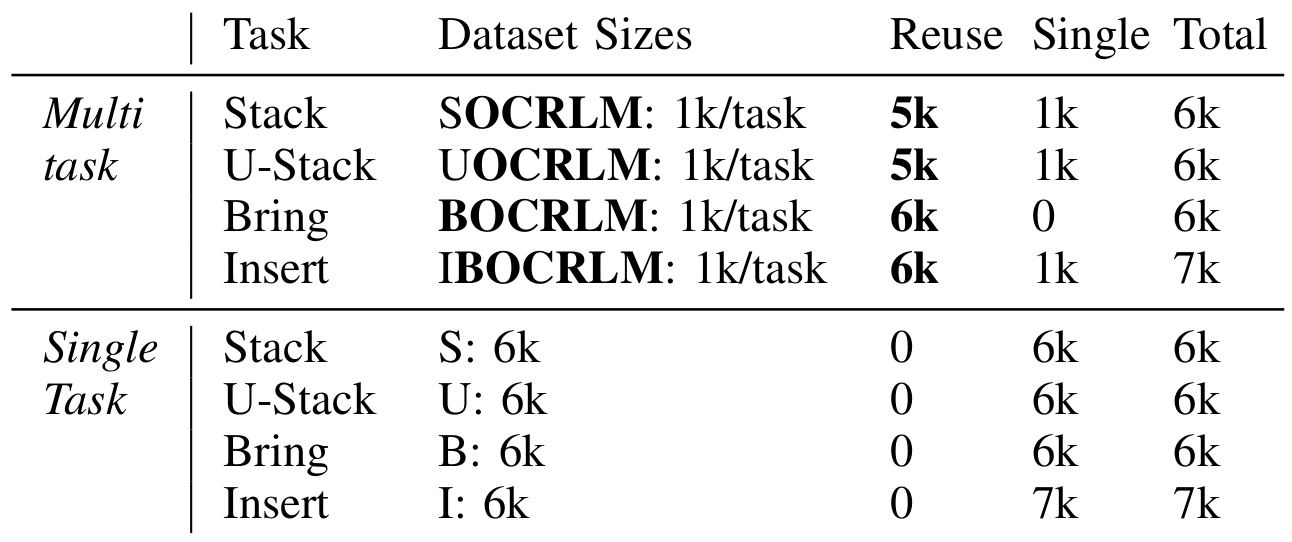
To try to make a fair comparison, we used an equivalent amount of total expert data for the single-task methods, as compared to the multitask methods. However, it is also important to note that the single-task methods cannot reuse data between tasks. The following table describes this idea in further detail:
Our main performance results are shown below.
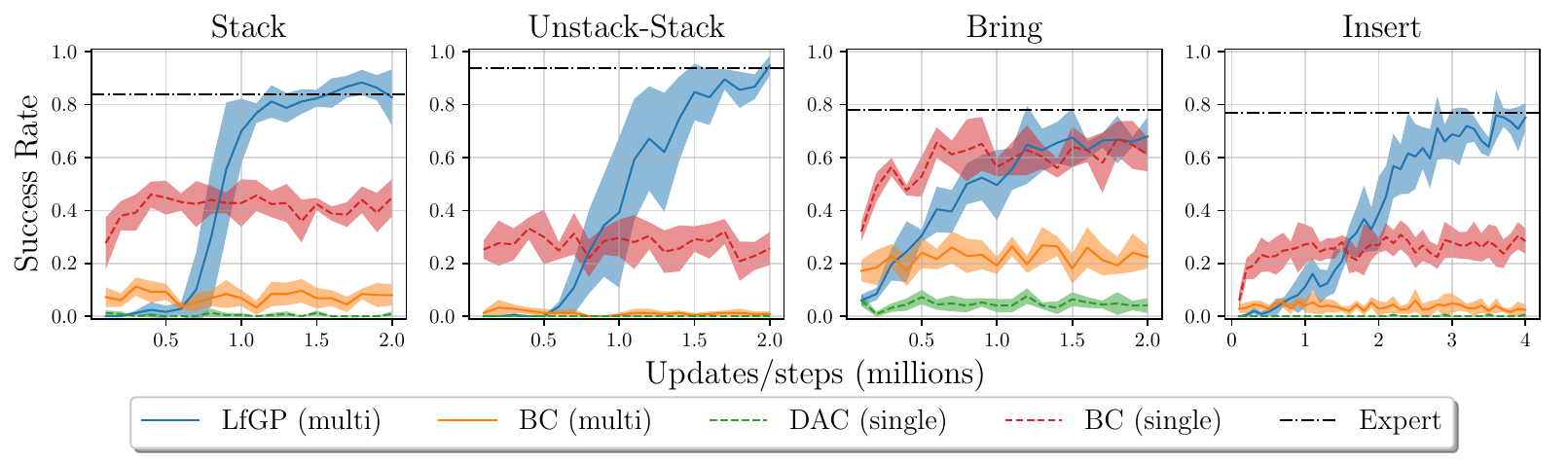
It is clear that LfGP is able to achieve expert-level behaviour in all tasks apart from Bring. In Bring, it nearly achieves expert performance, but is also matched by single-task BC. Remember, however, that single-task BC has far more main-task data than LfGP, and cannot reuse expert data, so LfGP is still more expert-data efficient than BC.
Final Learned Policies for All Methods
Here we visualize the final learned policies for all four methods and all four tasks. Each video shows five episodes on repeat.
| DAC | Multitask BC | Single-task BC | LfGP | |
| Stack | ||||
| Unstack Stack | ||||
| Bring | ||||
| Insert |
Ablation Studies
We performed an extensive series of ablation experiments:
- Dataset ablations:
- Half the original dataset size
- 1.5x the original dataset size
- Subsampling the expert dataset, taking every 20th \((s,a)\) pair.
- Without added extra final \((s_T, \boldsymbol{0})\) pairs
- Scheduler ablations:
- Weighted Random Scheduler with Handcrafted trajectories (WRS + HC)
- Weighted Random Scheduler only
- Learned Scheduler
- No Scheduler (only main task selected)
- Sampling ablations:
- Expert sampling for discriminator only
- No sampling bias for \((s_T, \boldsymbol{0})\) pairs
- Baseline Alternatives:
- BC with early stopping (70%/30% training/validation split)
- GAIL (on-policy AIL)
For more description of these ablations, please see our paper. The results of these ablations are shown below.

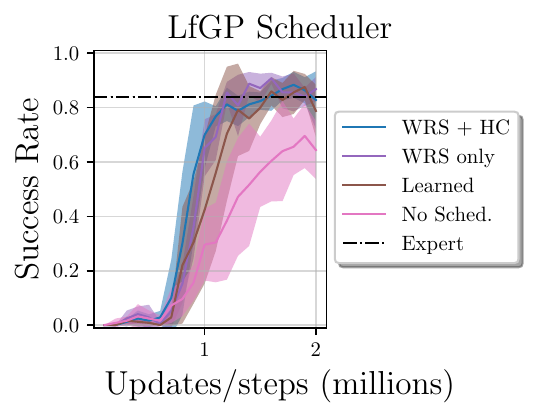
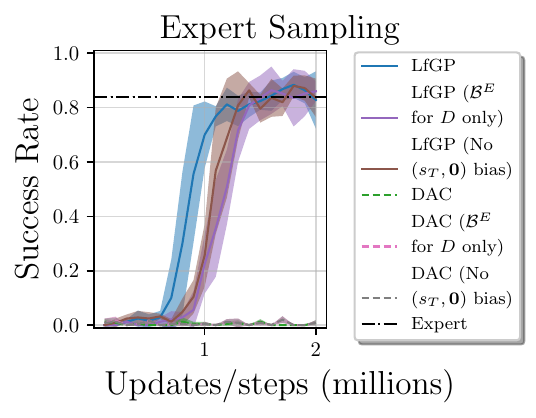
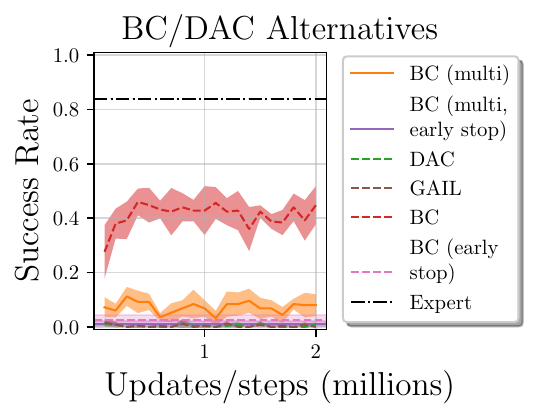
Analysis
We also visualized the learned stack models for LfGP and DAC.
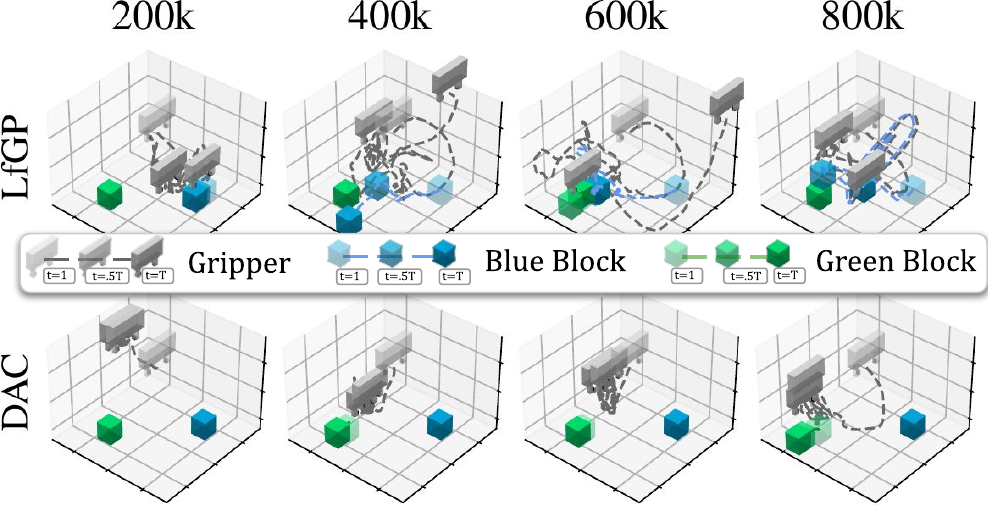
The LfGP policies exhibit significantly more diversity than the DAC policies do, and the DAC policies eventually only learn to partially reach the blue block and hover near the green block. This is understandable—DAC has learned a deceptive reward for hovering above the green block regardless of the position of the blue block, because it hasn’t sufficiently explored the alternative of grasping and moving the blue block closer. Even if hovering above the green block doesn’t fully match the expert data, the DAC policy receives some reward for doing so, as evidenced by its learned Q-Value (DAC on the right-most image):

Again, compared with DAC, the LfGP policies have made significantly more progress towards each of their individual tasks than DAC has, and the LfGP Stack policy, in particular, has already learned to reach and grasp the block, while learning high value for being near either block. Further on in training, it learns to only have high value near the green block after having grasped the blue block; an important step that DAC never achieves.
Code
Available on GithubNeurips 2021 Deep Reinforcement Learning Workshop Presentation
Citation
@article{2023_Ablett_Learning,
author = {Trevor Ablett and Bryan Chan and Jonathan Kelly},
code = {https://github.com/utiasSTARS/lfgp},
doi = {10.1109/LRA.2023.3236882},
journal = {IEEE Robotics and Automation Letters},
month = {March},
number = {3},
pages = {1263--1270},
site = {https://papers.starslab.ca/lfgp/},
title = {Learning from Guided Play: Improving Exploration for Adversarial Imitation Learning with Simple Auxiliary Tasks},
url = {https://arxiv.org/abs/2301.00051},
volume = {8},
year = {2023}
}
Bibliography
-
I. Kostrikov, K. K. Agrawal, D. Dwibedi, S. Levine, and J. Tompson, “Discriminator-Actor-Critic: Addressing Sample Inefficiency and Reward Bias in Adversarial Imitation Learning,” presented at the Proceedings of the International Conference on Learning Representations (ICLR’19), New Orleans, LA, USA, May 2019. ↩ ↩2
-
A. Ecoffet, J. Huizinga, J. Lehman, K. O. Stanley, and J. Clune, “First return, then explore,” Nature, vol. 90, no. 7847, pp. 580–586, Feb. 2021. ↩
-
M. Riedmiller et al., “Learning by Playing: Solving Sparse Reward Tasks from Scratch,” in Proceedings of the 35th International Conference on Machine Learning (ICML’18), Stockholm, Sweden, Jul. 2018, pp. 4344–4353. ↩