Seeing All the Angles: Learning Multiview Manipulation Policies for Contact-Rich Tasks from Demonstrations
Trevor Ablett, Daniel (Yifan) Zhai, Jonathan Kelly
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2021)
End-to-end learning has emerged as a popular alternative to the traditional sense-plan-act approach to robotic manipulation. This work was motivated by a relatively simple question: what happens when you try to apply an end-to-end visuomotor policy to a mobile manipulator, in which there is no guarantee that the base will always approach a task from the same relative pose?
We attempted to thoroughly answer this question by conducting experiments with a simulated and a real mobile manipulator. We generated fixed-view and multiview versions of a set of seven challenging and contact-rich tasks and collected human-expert data in each scenario. We then trained a neural network on each dataset, and tested the performance of fixed-view and multiview policies on fixed-view and multiview tasks.
We found that multiview policies, with an equivalent amount of data, not only significantly outperformed fixed-view policies in mulitview tasks, but performed nearly equivalently in fixed-view tasks. This seems to indicate that, given the ability to do so, it may always be worth training multiview policies. We also found that the features learned by our multiview policies tended to encode a higher degree of spatial consistency than those learned by fixed-view policies.

Tasks/Environments
As stated, we completed experiments in seven challenging manipulation tasks.
Data Collection
We collected data using a human expert for most of our environments using an HTC Vive hand tracker. For our simulated lifting environment, in the interest of creating repeatable experiments, we generated a policy using reinforcement learning. We created a simple method for autonomoulsy choosing randomized base poses between episodes, using:
- approximate calibration between the arm and the base,
- a known workspace center point, and
- approximate localization of the base, which we obtain using wheel odometry alone.
Notably, this information is required only for data collection as a convenience.
Results
As a reminder, we collected two different datasets for each task: a multiview dataset, where data is collected from the multiview task \( \mathcal{T}_m \), and a fixed-view dataset, where data is collected from the fixed-view task \( \mathcal{T}_f \).
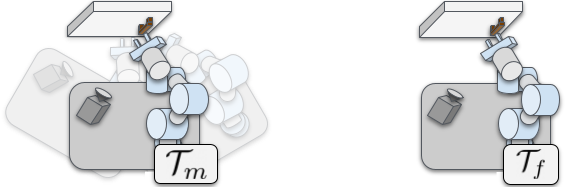
In this section, we refer to a multiview policy \( \pi_m \) and a fixed-view policy \( \pi_f \) as being trained on \( \mathcal{T}_m \) and \( \mathcal{T}_f \) respectively. Because \( \mathcal{T}_m \) and \( \mathcal{T}_f \) share an observation and action space, we can test \( \pi_m \) and \( \pi_f \) on both \( \mathcal{T}_m \) and \( \mathcal{T}_f \)!
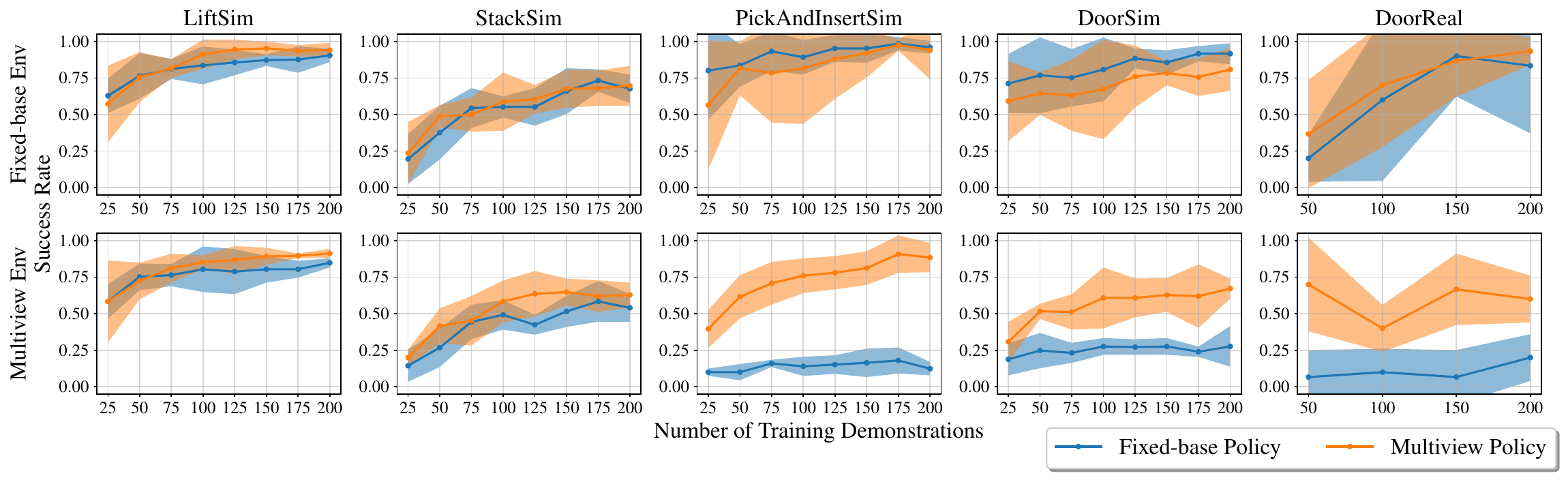
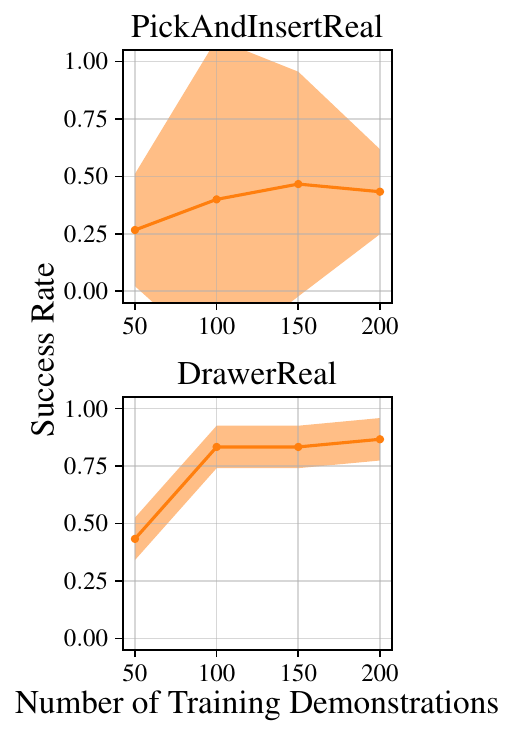
The results of \( \pi_m \) and \( \pi_f \) in \( \mathcal{T}_m \) and \( \mathcal{T}_f \) are shown above, where it is clear that \( \pi_m \) outperforms \( \pi_f \) in \( \mathcal{T}_m \), and, perhaps more surprisingly, \( \pi_m \) performs comparably to \( \pi_f \) in \( \mathcal{T}_f \), despite not having any data at the exact pose used for \( \mathcal{T}_f \). For PickAndInsertReal and DrawerReal, due to the high potential for environmental damage when running \( \pi_f \) in \( \mathcal{T}_m \), we only ran \( \pi_m \), but we would expect the pattern to be similar to PickAndInsertSim, DoorSim, and DoorReal.
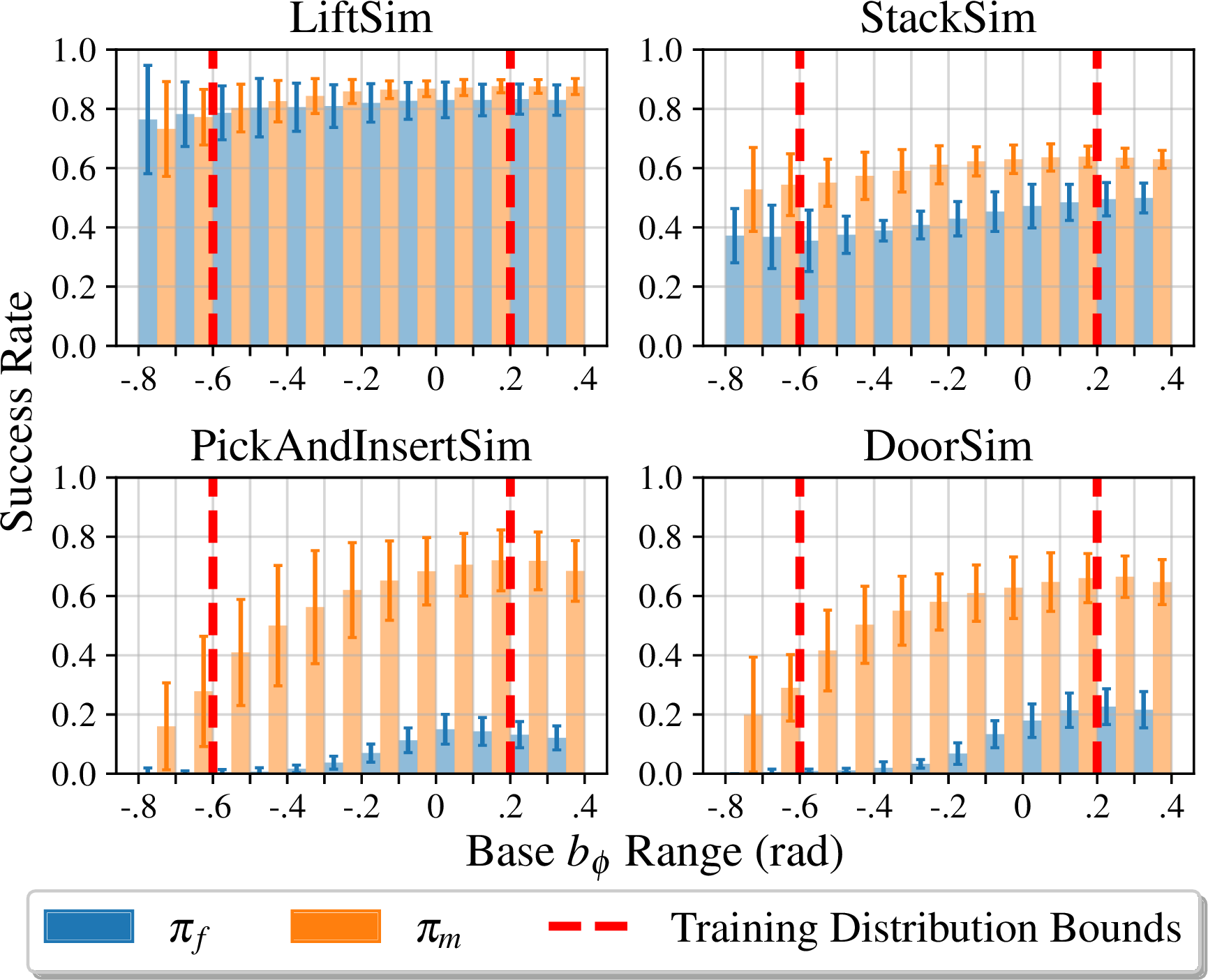
We also showed that \( \pi_m \) generalizes to out-of-distribution (OOD) data, while, for tasks where mutual information between poses is not generally high (see paper for more details), \( \pi_f \) performance drops dramatically as soon as the base is moved from \( b_\phi = 0\), the position at which it was trained.
Feature Analysis
Since our network structure includes a spatial-soft argmax layer1, which roughly corresponds to a spatial attention mechnanism, we can analyze the features that it learns.
Each of the features above are the two highest activating features learned by \( \pi_f \) running in \( \mathcal{T}_m \). Clearly, they display quite a bit of temporal and spatial spread. The following image shows the highest six activating features learned by \( \pi_f \):
In contrast, here are the two highest activating features learned by \( \pi_m \):
Clearly, the features display more consistency, indicating that the policy, without any loss enforcing it to do so, has learned a degree of view invariance. Once again, here are the six highest activating features:
For more details, be sure to check out our paper published at IROS 2021!
Code
Available on GithubIROS 2021 Presentation
Citation
@inproceedings{2021_Ablett_Seeing,
address = {Prague, Czech Republic},
author = {Trevor Ablett and Yifan Zhai and Jonathan Kelly},
booktitle = {Proceedings of the {IEEE/RSJ} International Conference on Intelligent Robots and Systems {(IROS)}},
code = {https://github.com/utiasSTARS/multiview-manipulation},
date = {2021-09-27/2021-10-01},
doi = {10.1109/IROS51168.2021.9636440},
pages = {7843--7850},
title = {Seeing All the Angles: Learning Multiview Manipulation Policies for Contact-Rich Tasks from Demonstrations},
url = {http://arxiv.org/abs/2104.13907},
video1 = {https://www.youtube.com/watch?v=oh0JMeyoswg},
year = {2021}
}
Bibliography
-
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,” Journal of Machine Learning Research, vol. 17, no. 39, pp. 1–40, 2016. ↩