Efficient Imitation Without Demonstrations via Value-Penalized Auxiliary Control from Examples
Trevor Ablett1, Bryan Chan2, Jayce Haoran Wang1, Jonathan Kelly1
1University of Toronto, 2University of Alberta
IEEE International Conference on Robotics and Automation (ICRA) 2025
Also presented as “Fast Reinforcement Learning without Rewards or Demonstrations via Auxiliary Task Examples”
Poster at Conference on Robot Learning (CoRL) 2024 Workshop on Mastering Robot Manipulation in a World of Abundant Data
Table of contents
Summary
Learning from examples of success is an appealing approach to reinforcement learning but it presents a challenging exploration problem, especially for complex or long-horizon tasks. This work introduces value-penalized auxiliary control from examples (VPACE), an algorithm that significantly improves exploration in example-based control by adding examples of simple auxiliary tasks.
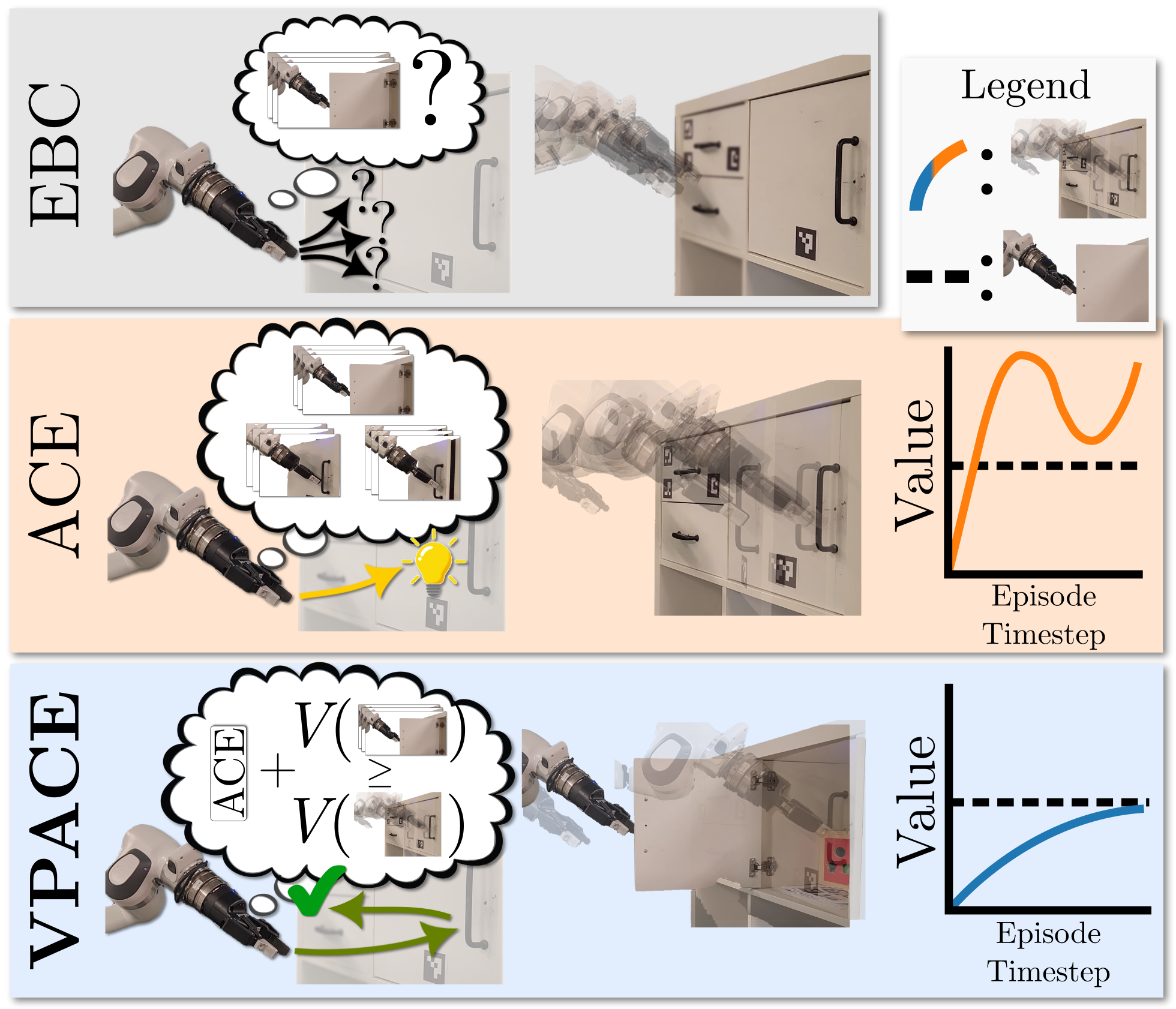
For instance, a manipulation task may have auxiliary examples of an object being reached for, grasped, or lifted. We show that the naı̈ve application of scheduled auxiliary control to example-based learning can lead to value overestimation and poor performance. We resolve the problem with an above-success-level value penalty. Across both simulated and real robotic environments, we show that our approach substantially improves learning efficiency for challenging tasks, while maintaining bounded value estimates. We compare with existing approaches to example-based learning, inverse reinforcement learning, and an exploration bonus. Preliminary results also suggest that VPACE may learn more efficiently than the more common approaches of using full trajectories or true sparse rewards.
Approach
VPACE boils down to three main changes to standard off-policy inverse reinforcement learning:
- Expert buffers are replaced with example states \( s^\ast \in \mathcal{B}^\ast \), where the only expert data provided to the agent are examples of successfully completed tasks.
- Auxiliary task data is provided, in addition to main task data, following the design established by SAC-X5 (for RL) and LfGP 6 (for IRL).
- To mitigate highly erroneous value estimates derived from bootstrapping, exacerbated by the addition of auxiliary task data, we introduce a simple scheme for value penalization based on the current value estimate for example states.
We find that our approach improves performance and efficiency both with a separately learned reward function (as in DAC3), and without (as in SQIL1, RCE2, and SQIL with an exploration bonus 4).
For more details on our approach, see our corresponding paper.
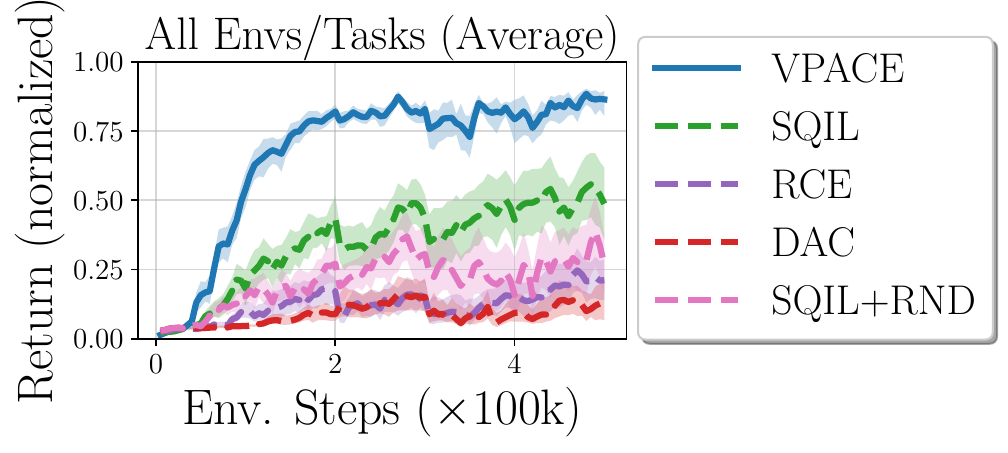
Real Panda Results
Exploratory Episodes over Time
Door
Drawer
Success Examples for Training
The numerical state data corresponding to these example success images was the only signal (i.e., no reward function and no full trajectories) used for training policies in this work. We also show examples from the initial state distributions.
Final Performance
Simulation Results
Exploratory Episodes over Time
Unstack-Stack
Insert
sawyer_drawer_open
sawyer_box_close
sawyer_bin_picking
hammer-human-v0-dp
relocate-human-v0-najp-dp
Success Examples for Training
The numerical state data corresponding to these example success images was the only signal (i.e., no reward function and no full trajectories) used for training policies in this work. We also show examples from the initial state distributions.
Panda Tasks
Sawyer Tasks
Adroit Hand Tasks
The same data was used for the original and the delta-position variants.
Final Performance (All Tasks)
Panda Tasks
Sawyer Tasks
Adroit Hand Tasks
Code
Available on GithubCitation
Check back soon!
Bibliography
-
S. Reddy, A. D. Dragan, and S. Levine, “SQIL: Imitation Learning Via Reinforcement Learning with Sparse Rewards,” in 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 ↩ ↩2 ↩3
-
B. Eysenbach, S. Levine, and R. Salakhutdinov, “Replacing Rewards with Examples: Example-Based Policy Search via Recursive Classification,” in Advances in Neural Information Processing Systems (NeurIPS’21), Virtual, Dec. 2021 ↩ ↩2
-
I. Kostrikov, K. K. Agrawal, D. Dwibedi, S. Levine, and J. Tompson, “Discriminator-Actor-Critic: Addressing Sample Inefficiency and Reward Bias in Adversarial Imitation Learning,” in Proceedings of the International Conference on Learning Representations (ICLR’19), New Orleans, LA, USA, May 2019. ↩ ↩2
-
Y. Burda, H. Edwards, A. Storkey, and O. Klimov, “Exploration by Random Network Distillation,” in International Conference on Learning Representations (ICLR’19), New Orleans, LA, USA: arXiv, May 2019. doi: 10.48550/arXiv.1810.12894. ↩ ↩2
-
M. Riedmiller et al., “Learning by Playing Solving Sparse Reward Tasks from Scratch,” in Proceedings of the 35th International Conference on Machine Learning (ICML’18), Stockholm, Sweden, Jul. 2018, pp. 4344–4353. Accessed: Jan. 10, 2021. ↩
-
T. Ablett, B. Chan, and J. Kelly, “Learning From Guided Play: Improving Exploration for Adversarial Imitation Learning With Simple Auxiliary Tasks,” IEEE Robotics and Automation Letters, vol. 8, no. 3, pp. 1263–1270, Mar. 2023, doi: 10.1109/LRA.2023.3236882. ↩